
为什么需要 Kubernetes?
当你只有 5 个容器时,手动管理完全可行。但在生产环境中:
Kubernetes(K8s)就是解决这些问题的容器编排系统。 它是一个自动化的"超级管家",负责在集群中调度、管理、监控和修复容器。
Master-Worker 主从架构
Kubernetes 集群的节点分为两种角色:
┌──────────────────────────────────────────────┐
│ Control Plane (Master) │
│ │
│ ┌──────────┐ ┌──────┐ ┌──────────────┐ │
│ │API Server│ │ etcd │ │Controller Mgr│ │
│ └──────────┘ └──────┘ └──────────────┘ │
│ ┌──────────┐ │
│ │Scheduler │ │
│ └──────────┘ │
└──────────────────────────────────────────────┘
│ │ │
┌────┴────┐ ┌────┴────┐ ┌────┴────┐
│Worker-01│ │Worker-02│ │Worker-03│
│┌───────┐│ │┌───────┐│ │┌───────┐│
││Kubelet││ ││Kubelet││ ││Kubelet││
│├───────┤│ │├───────┤│ │├───────┤│
││K-proxy││ ││K-proxy││ ││K-proxy││
│├───────┤│ │├───────┤│ │├───────┤│
││contd ││ ││contd ││ ││contd ││
│└───────┘│ │└───────┘│ │└───────┘│
└─────────┘ └─────────┘ └─────────┘
Control Plane(控制面 / Master 节点):负责决策和管理。不运行业务容器,只负责指挥调度。
Worker Node(数据面 / 工作节点):负责实际运行业务容器,接受控制面的指令。
控制面四大组件详解
API Server —— 集群的唯一入口
职责:所有的操作请求(不管是外部的 kubectl 命令、还是内部组件之间的通信)都必须经过 API Server。它是整个集群唯一的"咽喉要道"。
为什么这样设计:
安全审计:所有操作经过统一入口,可以做认证(你是谁)、授权(你有没有权限)、准入控制(你的操作是否合规)
解耦:组件之间不直接通信,任何组件故障都不会导致连锁崩溃
技术细节:
API Server 是一个 RESTful HTTP 服务,监听在 6443 端口(HTTPS)
所有资源操作都是标准的 HTTP 动词:GET(查询)、POST(创建)、PUT(更新)、DELETE(删除)
支持 Watch 机制:组件可以"订阅"资源变化,实时收到通知
etcd —— 集群的"数据库"
职责:存储集群的所有状态数据。节点信息、Pod 定义、Service 配置、Secret 密钥——一切都存在 etcd 里。
关键特性:
分布式 Key-Value 存储,支持高可用(生产环境通常部署 3 或 5 个 etcd 节点)
使用 Raft 共识算法保证数据一致性
支持 Watch 机制,数据变化时主动通知订阅者
为什么这么重要:etcd 是集群的"记忆"。即使整个集群断电重启,只要 etcd 的数据完好,K8s 就能照着 etcd 中记录的"期望状态"把所有服务恢复原样。
[!WARNING] etcd 是整个集群中最关键的组件。如果 etcd 数据丢失且没有备份,集群将无法恢复。生产环境必须定期备份 etcd。
Controller Manager —— 自动化控制循环
职责:持续监控集群的"实际状态"与"期望状态"是否一致,如果不一致就自动修复。
控制循环(Control Loop)的工作方式:
无限循环 {
实际状态 = 从 API Server 获取当前情况
期望状态 = 从 API Server 获取用户定义的期望
if (实际状态 ≠ 期望状态) {
执行操作使实际状态趋向期望状态
}
}
举例:你定义了一个 Deployment 要求 3 个副本。如果某个 Pod 崩溃了,实际副本变成 2 个,Controller Manager(具体是 ReplicaSet Controller)会立刻发现差异,并通知 API Server 创建一个新 Pod 来补齐。
这就是 K8s 的核心哲学——声明式管理:你只需要告诉 K8s"我要什么"(期望状态),它会自动想办法达到和维持这个状态,而不需要你告诉它"怎么做"。
Scheduler —— 智能调度器
职责:当有新的 Pod 需要创建时,决定它应该运行在哪个 Worker 节点上。
调度决策过程:
过滤(Filtering):排除不满足条件的节点(资源不足、有污点、不匹配亲和性规则等)
评分(Scoring):对剩余的可用节点打分,选择最优的节点
绑定(Binding):将 Pod 分配到得分最高的节点
评分考虑因素:
节点剩余资源(CPU、内存)
Pod 亲和性/反亲和性规则
数据局部性(Pod 使用的存储卷在哪个节点上)
负载均衡(尽量让各节点负载均匀)
数据面两大组件详解
Kubelet —— 节点代理
职责:运行在每个 Worker 节点上,是控制面在基层的"代言人"。
核心工作:
持续向 API Server 注册并汇报节点状态(心跳机制,默认每 10 秒一次)
接收 API Server 的指令,调用容器运行时(Containerd)来创建、启动、停止容器
执行探针检查(Liveness / Readiness),判断容器是否健康
管理容器的日志和资源使用情况
关键理解:Kubelet 挂了≠容器挂了。Kubelet 宕机只意味着控制面失去了对该节点的管理能力(节点变为 NotReady),但已经运行的容器进程不受影响——因为容器的父进程是 containerd-shim,不是 Kubelet。
Kube-proxy —— 网络规则管理器
职责:在每个节点上维护网络规则,实现 Service(服务)的负载均衡和网络转发。
工作模式:
iptables 模式(默认):通过修改 Linux 的 iptables 规则来实现流量转发
IPVS 模式(高性能):使用 Linux 内核的 IPVS(IP Virtual Server)模块,性能更好,适合大规模集群
举例:当你创建一个 Service 指向 3 个 Pod 时,kube-proxy 会在每个节点上创建相应的 iptables/IPVS 规则,使得任何节点上的进程访问 Service IP 时,流量会被均匀分发到这 3 个 Pod。
完整请求生命周期
从你在键盘敲下 kubectl apply -f nginx.yaml 开始,背后发生了什么:
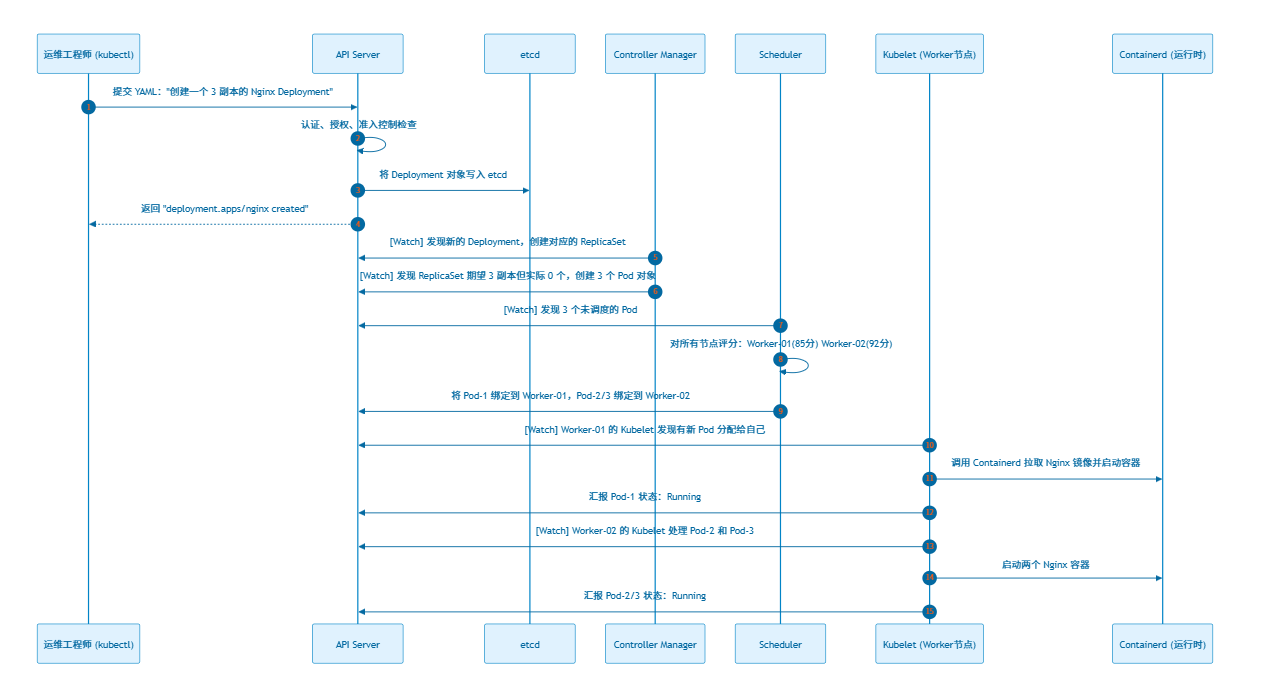
[!NOTE] 整个流程中,所有组件都只和 API Server 通信,组件之间互不直接联系。这种 Hub-and-Spoke(轮辐式) 架构保证了高度解耦:任何一个组件故障,其他组件不受影响。
节点初始化
环境规划
克隆虚拟机后的 Machine-ID 重置
# === 在所有节点均须执行 ===
sudo rm -f /etc/machine-id /var/lib/dbus/machine-id
sudo dbus-uuidgen --ensure=/etc/machine-id
sudo dbus-uuidgen --ensure为什么
machine-id 是 Linux 系统的全局唯一标识符。当你在 Proxmox VE 或 VMware 中通过"克隆"方式创建多台虚拟机时,所有克隆出来的 VM 会共享完全相同的 machine-id。
Kubernetes 的 CNI 网络插件(如 Calico)依赖 machine-id 来区分不同的节点。如果多个节点的 machine-id 相同,Calico 会认为它们是同一台机器,导致:
路由表混乱,形成"路由黑洞"
Pod 跨节点通信完全失败
kubectl get nodes可能只显示一个节点
不做会怎样
集群搭建时看起来正常,但部署 CNI 后 Pod 网络不通。这个 Bug 极其隐蔽,因为错误表现为网络问题,而根因却在 machine-id 上,排查方向完全错误。
验证
# === 在所有节点均须执行 ===
# 确认 ID 各不相同
cat /etc/machine-id主机名设置与 Hosts 解析
# === 在 172.16.11.118 上执行 ===
sudo hostnamectl set-hostname master-01
# === 在 172.16.11.119 上执行 ===
sudo hostnamectl set-hostname worker-01
# === 在 172.16.11.120 上执行 ===
sudo hostnamectl set-hostname worker-02# === 在所有节点均须执行 ===
# 写入集群的主机名解析表
cat <<EOF | sudo tee -a /etc/hosts
172.16.11.118 master-01
172.16.11.119 worker-01
172.16.11.120 worker-02
EOF为什么
Kubernetes 使用主机名(hostname)作为节点的身份标识。当 Kubelet 启动时,它会以当前主机名向 API Server 注册自己。如果两台机器的主机名相同(比如克隆后都叫 ubuntu),后注册的节点会覆盖前一个,导致 kubectl get nodes 只显示一个节点。
写入 /etc/hosts 是为了让所有节点能通过主机名互相解析到 IP 地址。虽然内网 DNS 也能做到,但直接写 hosts 更可靠——不依赖任何外部服务。在 K8s 集群中,控制面需要频繁通过主机名与各节点通信,如果 DNS 服务短暂故障,整个集群的管理能力就会瘫痪。
# === 在所有节点均须执行 ===
# 验证主机名已生效
hostname
# 验证能通过主机名 ping 通其他节点
ping -c 2 master-01
ping -c 2 worker-01
ping -c 2 worker-02关闭 Swap(虚拟内存交换分区)
# === 在所有节点均须执行 ===
# 立即关闭当前的 Swap
sudo swapoff -a
# 永久关闭:注释掉 /etc/fstab 中的 swap 行,防止重启后恢复
sudo sed -i '/swap/s/^/#/' /etc/fstabK8s默认拒绝在启用了Swap的节点上运行,开启Swap导致内存资源计算不准确,进而引发Pod运行卡顿或者调度逻辑异常。如果开启的话就会报错"Running with swap on is not supported, please disable swap"
验证
# === 在所有节点均须执行 ===
# 确认 Swap 已关闭(Swap 行应该全是 0)
free -h
# total used free
# Swap: 0B 0B 0B
加载内核模块与设置网络参数
# === 在所有节点均须执行 ===
# 声明需要在系统启动时自动加载的内核模块
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
# 立即加载这两个模块(不用等重启)
sudo modprobe overlay
sudo modprobe br_netfilter为什么——逐项解释
overlay 模块
OverlayFS 是容器的分层文件系统驱动。Containerd 默认使用 OverlayFS 作为容器的存储后端,用来组装镜像的多层只读层和容器的可写层。
不加载会怎样:Containerd 无法创建容器的根文件系统,容器启动失败。
br_netfilter 模块
这个模块使 Linux 网桥(bridge)上的流量能够被 iptables 规则处理。
背景:Kubernetes 的 Service 网络依赖 iptables(或 IPVS)来做流量转发。当 Pod 的流量经过 Linux 网桥时,如果没有 br_netfilter 模块,这些流量会绕过 iptables 规则,导致 Service 的 ClusterIP 无法被正确转发。
不加载会怎样:Pod 可以直接通过 IP 互相通信,但通过 Service 名称或 ClusterIP 访问时会超时。
# 设置内核网络参数
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 立即生效
sudo sysctl --systemnet.bridge.bridge-nf-call-iptables = 1
开启后,网桥上的 IPv4 流量会经过 iptables 的 FORWARD 链。这是 br_netfilter 模块加载后需要配合开启的内核参数。
net.bridge.bridge-nf-call-ip6tables = 1
同上,但针对 IPv6 流量。
net.ipv4.ip_forward = 1
允许本机作为"路由器"转发不属于自己的 IP 数据包。在 Kubernetes 中,Pod 的流量需要跨节点转发(比如 Worker-01 上的 Pod 要访问 Worker-02 上的 Pod),节点必须充当路由器角色。
不开启会怎样:Pod 跨节点通信的数据包到达节点后被内核直接丢弃,跨节点 Pod 完全不通。
验证
# === 在所有节点均须执行 ===
# 验证模块已加载
lsmod | grep -E "overlay|br_netfilter"
# 验证内核参数已生效
sysctl net.bridge.bridge-nf-call-iptables
sysctl net.ipv4.ip_forward
# 输出应该都是 = 1安装 Containerd 容器运行时
从K8s 1.24版本以后开始,K8s正式移除了Docker的内置支持。
Docker的调用链:
Kubelet → dockershim → dockerd → containerd → runc → 容器进程Containerd调用链:
Kubelet → containerd → runc → 容器进程
直接使用 Containerd 跳过了 Docker 中间层,减少了不必要的性能开销和故障点
# === 在所有节点均须执行 ===
# 安装 containerd 及依赖
sudo apt-get update
sudo apt-get install -y containerd apt-transport-https ca-certificates curl gpg
# 生成默认配置文件
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml > /dev/null
# 关键修改 1:启用 SystemdCgroup
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
# 关键修改 2:替换 sandbox 镜像为阿里云源
sudo sed -i "s|registry.k8s.io/pause|registry.aliyuncs.com/google_containers/pause|g" /etc/containerd/config.toml
# 重启 containerd 并设置开机自启
sudo systemctl restart containerd
sudo systemctl enable containerd为什么要设置 SystemdCgroup = true
Kubelet 默认使用 systemd 作为 Cgroup 驱动。如果 Containerd 仍然使用默认的 cgroupfs 驱动,两者会产生冲突——系统中同时存在两套 Cgroup 管理机制,导致资源限制和回收出现不一致。
不设置会怎样:Kubelet 日志报错:
Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\"
为什么要替换 sandbox 镜像
每个 Pod 启动时,Containerd 会先创建一个极小的 pause 容器(也叫 sandbox 容器/基础设施容器)来占住 Pod 的网络命名空间。默认的 pause 镜像托管在 registry.k8s.io,国内无法直接访问。
不替换会怎样:在我们实际部署中遇到了这个问题——所有控制面组件(API Server、etcd、Scheduler)反复崩溃重启,kubelet 日志中出现大量 DeadlineExceeded 错误。根因就是 containerd 在尝试拉取 registry.k8s.io/pause:3.10.1 时超时。
[!WARNING] containerd 的配置文件中有两个容易混淆的字段:
sandbox(旧式的 CRI 插件配置)和sandbox_image(新版配置)。它们可能同时存在,导致修改了一个但另一个仍然指向官方源。正确的做法是用containerd config default重新生成完整配置,然后做全局替换。
验证
# 验证 containerd 运行正常
sudo systemctl status containerd
# 验证配置中 SystemdCgroup 已开启
grep "SystemdCgroup" /etc/containerd/config.toml
# 验证 sandbox 镜像已替换为阿里云源
containerd config dump | grep sandbox安装 kubeadm / kubelet / kubectl
# === 在所有节点均须执行 ===
# 导入阿里云 Kubernetes 仓库的 GPG 密钥
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/Release.key \
| sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# 添加阿里云 Kubernetes 仓库
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/ /" \
| sudo tee /etc/apt/sources.list.d/kubernetes.list
# 安装三大组件
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
# 锁定版本,防止系统自动升级导致版本不兼容
sudo apt-mark hold kubelet kubeadm kubectl
# 启动 kubelet(此时它会反复重启,这是正常的,因为还没有初始化集群)
sudo systemctl enable --now kubelet三大组件是什么
为什么要锁定版本?
K8s 的版本兼容有严格要求:kubelet 版本不能高于 API Server 版本,控制面组件之间的版本偏差不能超过一个小版本。如果系统自动把 kubelet 从 1.30 升级到了 1.31 而 API Server 还在 1.30,集群可能出现不兼容问题。
验证
# 确认三个组件都已安装
kubeadm version
kubelet --version
kubectl version --client故障排查速查表
检查点 —— 真实验证输出
完成本实验所有操作后,在每个节点上执行以下验证。下面展示的是我们在实验环境 master-01 (172.16.11.118) 上实际执行的输出结果:
Machine-ID

每台节点的输出应该是一个 32 位的十六进制字符串,且三台节点各不相同。如果两台节点的值一样,说明克隆后没有重置 machine-id。
主机名

应该显示你在
hostnamectl set-hostname中设置的名称。
Swap 状态

关键看 Swap 那一行,三个值必须全部是
0B。如果不是 0,说明swapoff -a没有执行或/etc/fstab中的 swap 条目没有注释掉。
内核模块

必须同时看到
br_netfilter和overlay两行。bridge是br_netfilter的依赖模块,自动加载。最后一列的数字表示模块被引用的次数,overlay的11说明有 11 个容器正在使用 OverlayFS。
内核网络参数

三个值必须全部等于
1。如果为0,说明sysctl --system没有执行或/etc/sysctl.d/k8s.conf文件内容有误。
Containerd 运行状态

必须输出
active。如果是inactive或failed,用journalctl -u containerd -n 20查看错误日志。
SystemdCgroup 配置

必须是
true。如果是false或找不到这一行,说明sed替换没有生效。
Sandbox 镜像配置

sandbox 的值必须指向阿里云镜像(
registry.aliyuncs.com),而不是默认的registry.k8s.io。注意这里用的是containerd config dump(运行时实际配置),不是直接看配置文件——只有 dump 的输出才是 containerd 真正使用的值。
三大组件版本

三个组件的版本号必须一致(这里都是 v1.30.14)。
kubeadm version输出的详细信息中,Platform: linux/amd64表示这是 64 位 x86 架构的构建版本。
搭建集群
kubeadm init 初始化控制面
#仅在master上节点执行
sudo kubeadm init \
--pod-network-cidr=10.244.0.0/16 \
--image-repository=registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.30.14
# --pod-network-cidr=10.244.0.0/16 Pod网络的IP地址段,是默认地址段
#--image-repository=registry.aliyuncs.com/google_containers 指定为阿里云镜像源
#--kubernetes-version=v1.30.14 指定安装的K8s版本等待后,看到出现一串token和一串sha256的字段就成功了
kubeadm init 背后做了什么
执行这一条命令,背后自动完成了大量工作:
预检(Preflight):检查系统环境是否满足要求(Swap 是否关闭、端口是否冲突、内核模块是否加载等)
生成 PKI 证书:在
/etc/kubernetes/pki/下创建 CA 根证书、API Server 证书、etcd 证书等生成 kubeconfig 文件:创建 admin.conf、kubelet.conf、scheduler.conf 等配置文件
创建静态 Pod 清单:在
/etc/kubernetes/manifests/下写入 API Server、etcd、Controller Manager、Scheduler 的 Pod YAML 文件启动控制面组件:Kubelet 检测到 manifests 目录中的 YAML 后,自动创建并启动这些 Pod
配置集群内部组件:部署 CoreDNS、kube-proxy 等
生成 Join Token:输出 Worker 节点加入集群的命令
配置 kubectl 管理凭据
初始化成功后,需要将管理配置复制到用户目录:
# === 在 Master 节点上执行 ===
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 查看节点(此时只有 Master,状态为 NotReady——因为还没有 CNI)
kubectl get nodes
# 查看控制面 Pod 状态(应该全部 Running)
kubectl get pods -n kube-systemWorker 节点加入集群
根据kubeadm init成功所输出的token和sha256:<hasbh值>,构建一条join命令
#在所有的woker节点输入这条指令
sudo kubeadm join <master_IP:6443>\
--token <token值> \
--discovery-token-ca-cert-hash sha256:<hash值>
#token只有24小时的有效期,如果过期可以申请一个
sudo kubeadm token create --print-join-command[!WARNING] 必须使用
sudo。非 root 用户执行此命令会因为无法读取/etc/kubernetes/admin.conf而卡死无响应。
Worker 加入前的清理
如果 Worker 之前尝试过加入(失败或加入过其他集群),必须先清理:
# === 在需要清理的节点(如加入失败的 Worker)上执行 ===
# 重置 kubeadm 状态(会停止 kubelet 并清理配置)
sudo kubeadm reset -f
# 清理残留的 CNI 配置
sudo rm -rf /etc/cni/net.d
# 清理 iptables 规则
sudo iptables -F && sudo iptables -t nat -F && sudo iptables -t mangle -F常见报错:[ERROR Port-10250]: Port 10250 is in use —— 说明 kubelet 还在运行(上次 join 的残留),kubeadm reset -f 会停止它。
静态 Pod 机制
控制面组件(API Server、etcd 等)不是通过 kubectl 部署的,而是以"静态 Pod"的方式运行。
工作原理:Kubelet 持续监视 /etc/kubernetes/manifests/ 目录。只要在这个目录下放入一个 YAML 文件,Kubelet 就会自动根据它创建 Pod;删除 YAML 文件,Pod 就会被销毁。
# === 在 Master 节点 (172.16.11.104) 上执行 ===
# 查看静态 Pod 的 YAML 文件
ls /etc/kubernetes/manifests/
# 输出: etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml网络插件
Kubernetes 对集群网络有三条硬性要求:
K8s 本身不实现这些网络功能,而是交给 CNI 插件来实现。常见的 CNI 插件有:
安装Calico
Calico 在每个节点上运行以下组件:
# === 在 Master 节点上执行 ===
# 如果项目根目录已有 calico.yaml 则直接使用
# 如果没有,从官方下载(可能需要代理):
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/calico.yaml
#找到 CALICO_IPV4POOL_CIDR 配置项并修改
sed -i 's|# - name: CALICO_IPV4POOL_CIDR|- name: CALICO_IPV4POOL_CIDR|' calico.yaml
#Calico的默认网段是192.168.0.0/16,修改成kubeadm init指定的10.244.0.0/16
sed -i 's|# value: "192.168.0.0/16"| value: "10.244.0.0/16"|' calico.yaml
#替换为国内的镜像源
sed -i 's|docker.io|docker.m.daocloud.io|g' calico.yaml
#部署服务
kubectl apply -f calico.yaml
#等待所有 calico Pod 变为 Running(通常需要 2-5 分钟)
kubectl get pods -n kube-system -l k8s-app=calico-node -w
#检查节点状态
kubectl get nodes
# 所有节点应该变为 Ready!安装Flannel
#走走代理
curl -O https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
#部署服务
kubectl apply -f kube-flannel.yml真诚建议配置Calico这个网络插件,可以限制Pod访问等更多功能
验证网络连通性
跨节点 Pod 通信测试
# === 在 Master 节点上执行 ===
# 创建两个测试 Pod,强制调度到不同节点
kubectl run test-pod-1 --image=docker.m.daocloud.io/library/busybox --restart=Never \
--overrides='{"spec":{"nodeName":"worker-01"}}' -- sleep 3600
kubectl run test-pod-2 --image=docker.m.daocloud.io/library/busybox --restart=Never \
--overrides='{"spec":{"nodeName":"worker-02"}}' -- sleep 3600
# 等待 Pod 就绪
kubectl wait --for=condition=Ready pod/test-pod-1 pod/test-pod-2 --timeout=120s
# 获取 Pod IP
kubectl get pods -o wide
# 从 test-pod-1 ping test-pod-2 的 IP
kubectl exec test-pod-1 -- ping -c 3 <test-pod-2的IP>
# 清理
kubectl delete pod test-pod-1 test-pod-2预期结果:ping 成功,说明跨节点 Pod 通信正常。
查看路由信息
# === 在集群任意节点上执行 ===
# 在任意节点上查看 Calico 生成的路由表
ip route | grep "10.244"
# 你会看到类似这样的路由:
# 10.244.37.192/26 via 172.16.11.120 dev eth0 proto bird
# 10.244.171.0/26 via 172.16.11.119 dev eth0 proto bird
# 这说明 BGP 已经在工作:发往 10.244.37.x 网段的流量会被路由到 172.16.11.120 (worker-02)
常见故障排查
故障 1:kubectl 报 connection refused
# === 在 Master 节点上执行 ===
# 第一步:检查 API Server 容器是否在运行
sudo crictl ps -a --name kube-apiserver
# 如果 STATE 是 Exited 且 ATTEMPT 数字很高,说明在反复崩溃重启
# 查看崩溃日志
sudo crictl logs <容器ID>
# 常见根因:
# 1. etcd 未启动 → 检查 etcd 容器状态
# 2. sandbox 镜像拉取失败 → containerd config dump | grep sandbox
# 3. 证书问题 → 检查 /etc/kubernetes/pki/ 下证书是否完整故障 2:API Server 反复 CrashLoopBackOff
# === 在 Master 节点上执行 ===
# 查看 kubelet 日志(能看到更底层的错误)
sudo journalctl -u kubelet -n 50 --no-pager
# 常见日志模式:
# "failed to get sandbox image" → sandbox 镜像配置错误
# "DeadlineExceeded" → 镜像拉取超时(网络问题)
# "rbac/bootstrap-roles failed" → API Server 无法连接自己(IPv6 问题)故障 3:节点一直 NotReady
# === 在 Master 节点上执行 ===
# 在 Master 上查看节点详情
kubectl describe node <节点名>
# 看 Conditions 部分的 Ready 条件
# 常见原因:
# - "NetworkPluginNotReady" → CNI 未部署(正常,下一课解决)
# - "KubeletNotReady" → kubelet 未运行 → journalctl -u kubelet 查看原因故障 4:Worker 加入失败
# === 在 Worker 节点上执行 ===
# 在 Worker 上查看 kubelet 日志
sudo journalctl -u kubelet -n 30 --no-pager
# 常见原因:
# - Token 过期 → Master 上重新生成
# - 端口被占 → kubeadm reset -f 先清理
# - 网络不通 → ping Master IP 确认连通性
# - containerd sandbox 配置没改 → Worker 也需要改 sandbox 镜像源!